
2026-06-02T01:19:20+08:00
利用大数据洞察世界杯的不确定性
在现代足球世界里,世界杯不再只是球员在绿茵场上的对抗,也是数据、算法与计算力在“看不见的赛场”上较量。传统球迷凭经验、直觉或者媒体观点预测赛事结果,而如今,大数据技术尝试将这种“感觉”转化为可量化的概率评估。通过对历史比赛、球员状态、战术风格、比赛环境乃至社交媒体舆情的综合分析,研究者正在构建更精细的预测模型,以期在这项全球瞩目的赛事中捕捉到更多可解释的规律。这类研究不仅关乎猜测谁能夺冠,更在于探索:在高度复杂且偶然性极强的足球比赛中,数据与模型究竟能将不确定性压缩到何种程度。

大数据视角下的世界杯预测主题与意义
围绕“利用大数据技术对世界杯赛事结果的预测性研究”这一主题,核心问题并非简单的“谁能赢”,而是要回答:如何利用多源异构数据构建合理的预测框架,并在实际赛事中持续迭代和验证。这一研究方向的意义至少体现在三个方面。其一,对球队、教练组而言,基于数据的预测可为战术准备与轮换安排提供辅助决策,例如对特定对手的弱点分析、对关键球员疲劳度与伤病风险的预判。其二,对媒体及博彩机构而言,更严谨的概率模型可以降低主观偏见,形成更透明和可解释的赔率体系。其三,对学术与技术社区而言,世界杯提供了一个高关注度、开放度较高的实验场,研究者可以在其中验证机器学习、深度学习、贝叶斯建模等多种方法在真实复杂系统中的表现,从而推动数据科学与体育分析的交叉发展。

数据来源与特征构建是预测研究的基础
要进行有效的世界杯预测,首要任务是构建高质量的数据基础。通常,研究者需要整合多个层级的数据源:一是宏观层面的历史战绩,包括各届世界杯以及洲际赛事、友谊赛的结果,关注胜平负、进失球差、比赛时段等指标;二是球队层面的战术与表现数据,例如控球率、射门次数、预期进球值xG、反击频率、防守站位数据等,这类数据往往依托光学追踪系统与事件标注技术获取;三是球员个体数据,包括出场时间、跑动距离、关键传球、对抗成功率以及近期在俱乐部的表现;四是与比赛环境相关的数据,如气温、湿度、海拔、球场草皮类型、时区差异,以及裁判执法风格、黄红牌数据;五是舆情与心理层面数据,例如社交媒体上对球队和球员的态度情绪分析、更衣室内部矛盾传闻、伤病新闻传播强度等。通过对这些多维度数据进行清洗与特征工程,研究者可以构造出一系列用于模型训练的特征变量,如综合实力评分、比赛状态指数、疲劳风险评分、战术风格差异量化指标等,从而在模型层面更全面地刻画每一场世界杯比赛的背景。
常见预测模型与技术路径
在技术层面,世界杯赛事结果预测往往采用多模型融合的策略,以避免单一方法的偏差。传统统计方法如逻辑回归、泊松回归和多项式回归依然占有一席之地,特别是在预测进球数和胜平负概率方面。泊松模型常用于估计每支球队在特定对阵中的进球期望值,通过输入两队攻防强度、历史对阵记录等特征,进一步计算胜、平、负的概率。贝叶斯层次模型能够在样本有限的情况下,将球队与球员层面的不确定性纳入同一框架,逐步更新对各队真实实力的估计。随着计算力提升与数据规模增大,机器学习方法如随机森林、梯度提升树、XGBoost乃至深度学习中的神经网络、图神经网络逐渐成为主流选项。这些模型可以自动捕捉高维特征之间的非线性关系,尤其在处理复杂的战术与球员交互时表现更优。某些研究还结合蒙特卡洛模拟,在给定赛程与模型输出概率的前提下,对整个世界杯进行成千上万次模拟,从而估算每支球队进入淘汰赛、晋级四强甚至夺冠的概率,实现对赛事结果的全局性预测。
案例分析历史世界杯中的模型实践

在最近几届世界杯中,已经出现了多种基于大数据的预测案例,为研究提供了可参照的样本。例如有研究团队基于欧洲五大联赛和国家队比赛数据,为每名球员定义了一个动态的综合能力评分,再结合国家队阵容结构、战术适配度及教练风格,构建出球队整体实力分布模型。通过对比赛进行模拟,他们在赛前给出了各队晋级概率预测,与最终结果进行对比时发现,对于传统强队的晋级概率判断较为准确,但对黑马球队的爆冷表现预测存在明显偏差。这一案例提示我们:即便在大数据支撑下,模型依然对极端事件和结构性变革较为敏感,比如主教练临时更换战术体系、关键球员受伤或被停赛等情况,这些往往超出了历史数据的范畴。同样,有项目基于预期进球xG模型对世界杯小组赛进行了逐场预测,结果显示,在样本量较大的情况下,xG与实际进球之间存在较高的相关性,但在单场比赛中,门将发挥、门柱、风向等微小因素即可导致明显偏差,使得最终胜负结果与模型预期相悖。这些案例说明,大数据技术在宏观预测层面有一定优势,但在单场结果预测中,仍必须对偶然性保持足够敬畏。
特征选择与模型解释的关键挑战
世界杯预测研究中一个常被忽视却极其重要的环节,是特征选择与模型可解释性。在高维数据场景下,盲目地堆叠特征不仅会造成过拟合,还可能削弱模型对关键因素的识别能力。例如,如果同时引入大量相互高度相关的指标,如射门次数、射正次数和xG等,很可能会导致模型在训练集上表现优异,却在实际比赛中失效。在特征工程阶段,研究者需要结合足球专业知识,对各项指标进行降维、筛选与重构,将冗余信息合并成更具代表性的综合特征。在媒体传播和决策支持场景中,预测模型不只是给出一个概率数字,而要对“为什么是这个概率”提供合理解释。这时,一些解释性工具如SHAP值、特征重要性排序、局部可解释模型等就显得尤为关键,它们可以帮助分析某场比赛中球队实力差距、主场优势、球员伤缺等因素各自贡献了多少影响,从而让教练组和公众更容易接受和理解预测结果,而不仅仅把它视为一个“黑箱结论”。
数据质量与采集偏差对预测的影响
高精度预测并不只依赖于复杂模型,更依赖于数据质量与采集方式的可靠性。如果基础数据存在系统性偏差,再精密的算法也难以给出可信结果。例如,一些历史赛事的统计标准并不统一,早期的射门、关键传球、助攻等数据记录不完备,导致现代统计模型很难对不同年代的世界杯进行公平比较。不同联赛、不同统计公司可能采用不同的事件定义标准,这会使得跨数据源整合时出现隐形偏差。如果模型训练主要依赖欧洲俱乐部数据,那么在预测来自非洲或亚洲联赛球员表现时,其误差可能被放大。在世界杯这样多元文化和多联赛交汇的赛事中,如何保证数据标准的一致性、采集流程的透明性以及跨平台整合的可控性,是大数据研究必须正视的问题。为了缓解这些问题,研究者往往会采用数据对齐、标准化和多源交叉验证等方法,以减少数据噪声对预测结果的干扰。
将大数据预测融入战术与管理决策
从实践角度看,世界杯大数据预测价值的最终体现,不是在实验室里,而是在球队的战术准备和管理决策中落地。一个具备实用价值的预测系统,往往包括赛前情景分析、实时比赛监测以及赛后复盘三个环节。赛前,教练组可以借助预测模型了解对手在不同阵型下的防守漏洞、定位球防守习惯、边路防守强弱等,从而针对性地设计进攻方案;模型还可以帮助评估不同首发组合与换人策略对胜率的影响,辅助制定更科学的轮换计划。比赛过程中,实时数据分析系统可以监测球员跑动强度、对抗成功率以及对方战术调整,结合预设模型给出动态胜平负概率,从而为临场指挥提供参考。赛后,通过对模型预测与实际结果的对比,球队可以识别数据与现实偏差的来源,例如某位球员在大赛环境下心理状态波动较大,或者某套战术在高压对抗下失效,为下一阶段的训练和排兵布阵提供反馈。在这一过程中,大数据不是取代教练,而是成为教练的“第二视角”,帮助其跳出个人经验的局限,做出更全面的判断。
不确定性永存背景下的研究边界
尽管大数据技术为世界杯赛事预测带来了前所未有的精细度和系统性,但足球比赛本身具有极强的随机性与突发性,这种结构性不确定性决定了任何预测都只能给出概率,而无法保证绝对正确。一张偶然的红牌、一场突如其来的暴雨、一次门线技术的判罚,甚至是现场观众情绪的波动,都可能扭转比赛的走势。大数据研究需要在设计和传播时明确这一边界,避免把模型结果宣传为“命中注定”,而应将其视为一种基于历史与现实信息的理性估计。在学术层面,如何在尊重不确定性的前提下提升预测精度,如何用更完善的评价指标衡量模型表现,例如Brier分数、对数损失、校准曲线等,都是未来研究需要持续探索的方向。研究者还必须警惕模型被滥用于操纵舆论、误导公众甚至影响比赛公正性的风险,在推动技术创新的坚持透明性、伦理性与公平性的底线。通过这种方式,利用大数据技术对世界杯赛事结果的预测性研究,才能在实践与理论层面发挥出真正的价值
分享:
热门新闻
-
世界杯竞猜平台:掌握在线精准预测比赛结果的技巧
新闻资讯2026-07-19T01:18:21+08:00 -

世界杯竞猜平台最新福利活动
新闻资讯2026-07-19T01:18:21+08:00 -

2026世界杯实时比分查询平台精选推荐
新闻资讯2026-07-18T01:18:25+08:00 -
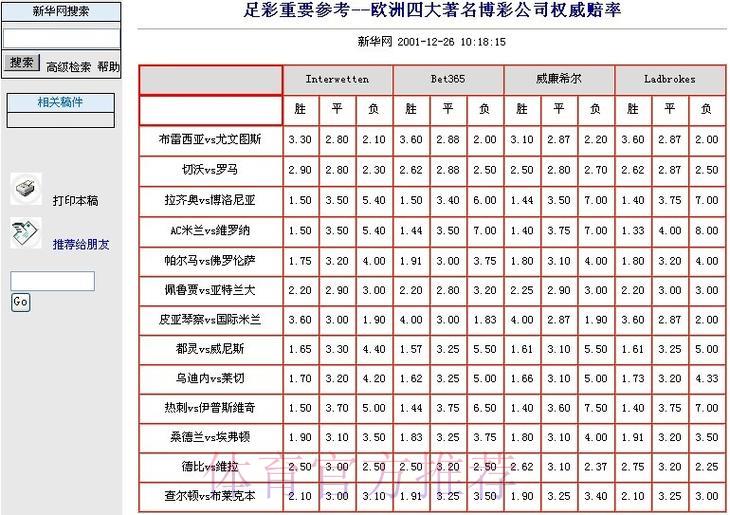
世界杯竞猜平台:掌握赔率变化规律与有效控制投注风险的实用技巧
新闻资讯2026-07-18T01:18:25+08:00